01
Thermal and environmental drift
Surface developing conditions before they become uptime events.
Temperature, humidity, water ingress, pressure, air-quality or other suitable signals can highlight conditions that degrade resilience over time.
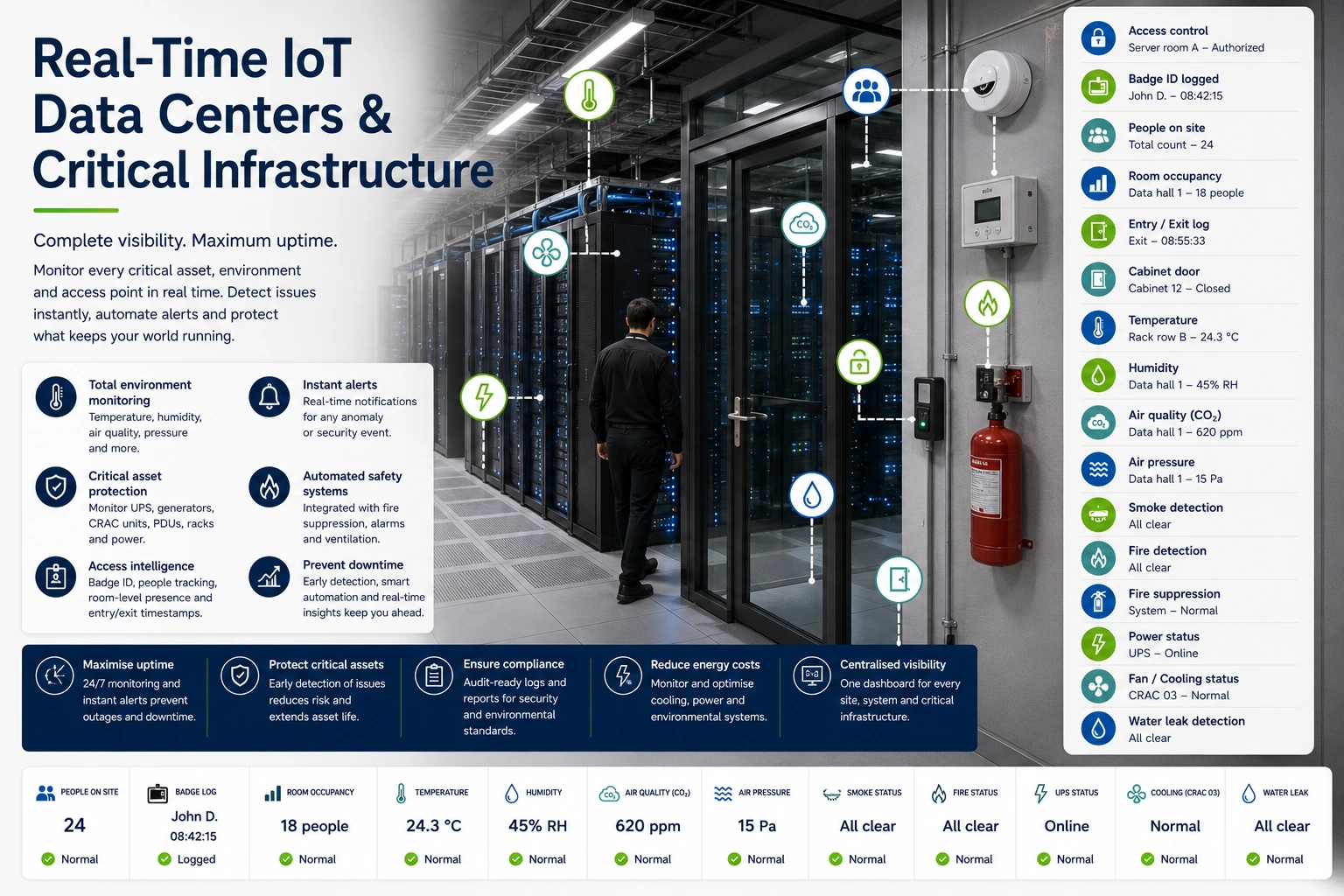
IoT monitoring for data centres and critical infrastructure where uptime, controlled access, thermal stability, cabinet state, plant conditions and evidence-ready incident records cannot tolerate blind spots.
IoT Technologies helps operators add independent sensing and telemetry across controlled environments, supporting earlier triage, clearer escalation and defensible evidence without disrupting existing BMS, DCIM or security systems.
Resilience and assurance telemetry
Focus monitoring on thermal drift, environmental change, access events, cabinet state and plant conditions that can affect resilience.
Design devices, gateways, mounting, cadence and handoff around site governance, change control and non-invasive installation needs.
Add event histories and corroborating telemetry where BMS, DCIM, security and contractor records do not provide the whole picture.
Track battery, signal, gateway state, missed payloads and data acceptance so the monitoring layer remains auditable.
Critical infrastructure monitoring is only useful when it strengthens operational control. The signal must be reliable, explainable and aligned with change-controlled response workflows.
Data centres and critical infrastructure are engineered for resilience, but resilience still depends on what operators can see and how quickly they can act. Incidents often begin as small signals: thermal drift, humidity change, abnormal access, cabinet movement, plant condition change or a weak pattern that becomes obvious only after the event.
Existing BMS, DCIM and security systems remain important, but they do not always provide a unified evidence layer across assets, contractors, cages, cabinets, plant spaces, perimeter zones and controlled rooms. A focused IoT layer can add independent corroboration where conventional systems do not reach or where additional operational evidence is valuable.
The deployment has to respect controlled-site reality. Installation should be predictable, non-invasive and aligned with change control. Devices, gateways, reporting cadence and access to data are shaped around the site rules rather than forcing a generic monitoring approach into a critical environment.
Thermal and environmental drift are common high-value signals. Temperature, humidity, air-quality, water ingress, pressure, airflow-adjacent signals or other environmental cues can help teams identify developing risk before thresholds, alarms or downtime events become more serious.
Access and activity signals can also strengthen assurance. Cage entry, cabinet access, plant-room doors, restricted-zone movement, tamper, equipment movement and contractor attendance can be captured as event histories where the deployment model and site policy support it.
Connectivity is engineered around hostile signal paths. Shielded areas, sub-floor spaces, plant rooms, concrete, metalwork and security constraints may require careful gateway placement and appropriate RF or backhaul choices, including 433 MHz, 868 MHz, LoRaWAN-style profiles, Ethernet, cellular or mixed architectures where suitable.
A strong monitoring layer also monitors itself. Device battery, signal strength, gateway health, last-seen time, missed payloads and acceptance status matter because teams need to know whether the evidence pathway is healthy, not just whether a sensor exists.
Evidence-grade reporting helps after an incident. Timelines showing what changed, when it changed, who was alerted, who acknowledged it, whether the device chain was healthy and what response followed can support investigation, supplier accountability, governance and assurance review.
The safest approach is a scoped pilot. We identify high-value zones and failure modes, validate coverage and cadence in plant, sub-floor and shielded areas, agree acceptance criteria, then scale the proven pattern across additional rooms, zones, cabinets and facilities.
Thermal and environmental drift
Temperature, humidity, water ingress, pressure, air-quality or other suitable signals can highlight conditions that degrade resilience over time.
Access governance
Door, cabinet, cage, plant-room, restricted-zone, tamper and movement events can support security, maintenance and contractor accountability workflows.
Plant and sub-floor areas
Sub-floor areas, plant rooms, risers, service corridors, perimeter zones and remote cabinets can be monitored where safe installation and signal paths are proven.
433 MHz and 868 MHz
433 MHz, 868 MHz, LoRaWAN-style profiles, Ethernet, cellular and mixed gateway architectures can be assessed around shielding, payload, backhaul and governance constraints.
Evidence-grade timelines
Event timestamps, acknowledgements, device health, gateway delivery and response notes help operators explain incidents and refine response.
Assurance reporting
Consistent reporting can support post-incident review, supplier conversations, governance, audits and continuous improvement without creating another silo.
Deployment approach
The right pilot proves signal quality, governance fit and evidence value before wider rollout.
We map critical zones, failure modes, access constraints and operational owners, then survey coverage, power, mounting and gateway geometry. Devices, alerts and reporting are configured around a representative pilot with clear acceptance criteria before scaling.
Define critical rooms, cabinets, cages, plant areas, access rules, environmental risks, response owners and evidence requirements.
Define zones
Check mounting, power, 433 MHz or 868 MHz coverage, gateway locations, shielding, backhaul and change-control constraints.
Map paths
Set sensors, thresholds, alert severity, acknowledgement routes, device-health checks, reporting cadence and evidence outputs.
Tune events
Run representative controlled zones through pilot acceptance, validating signal quality, alert usefulness and evidence value.
Assurance proof
Extend the proven pattern across additional rooms, zones, cabinets, plant spaces and facilities with consistent commissioning.
Controlled rollout
Bring the site zones, access requirements, environmental risks, governance constraints and reporting workflow. We will shape a pilot around measurable resilience and assurance value.
Plan a critical monitoring pilotApplications
Monitor temperature, humidity, access, movement, tamper and other exception signals where site policy and installation constraints allow.
Record cabinet access, cage activity, movement cues and equipment-state changes that support security and maintenance workflows.
Add visibility to hidden or constrained areas where environmental drift, water ingress or service conditions can affect resilience.
Surface gate, door, cabinet, zone and tamper events where independent evidence strengthens operational assurance.
Support handover records that show what changed, when attendance occurred and what evidence existed before and after work.
Maintain timelines of events, alerts, acknowledgements, device health and response notes for investigation and continuous improvement.
FAQ
An independent sensing layer across thermal conditions, access events, plant spaces and sub-floor areas that catches drift and anomalies between the views your BMS and DCIM already give you.
No. It deploys alongside them without integration dependencies or disruption — an independent evidence layer rather than a replacement for the systems already in control.
Low-power sensors read temperature behaviour in aisles, cabinets, plant rooms and sub-floor spaces continuously, surfacing drift and hot spots early enough for triage before they threaten uptime.
Yes. Access and movement exceptions in controlled zones are alerted in real time and recorded with timestamps, supporting access governance and review.
It produces evidence-grade timelines — what changed, when, who was alerted and what followed — which strengthens incident review, client assurance and audit preparation.
Share the site type, critical zones, access governance, thermal risks, plant spaces and reporting workflow. We will help scope a controlled pilot for exception alerts, evidence trails and operational assurance.
Direct contact
Location
Aylsham Business Park, Norwich
Norfolk NR11 6FD · VAT GB 409644484
Tell us about your critical spaces, thermal risks, access controls, cabinet or cage monitoring needs, plant areas, gateway constraints and reporting workflow.